









































































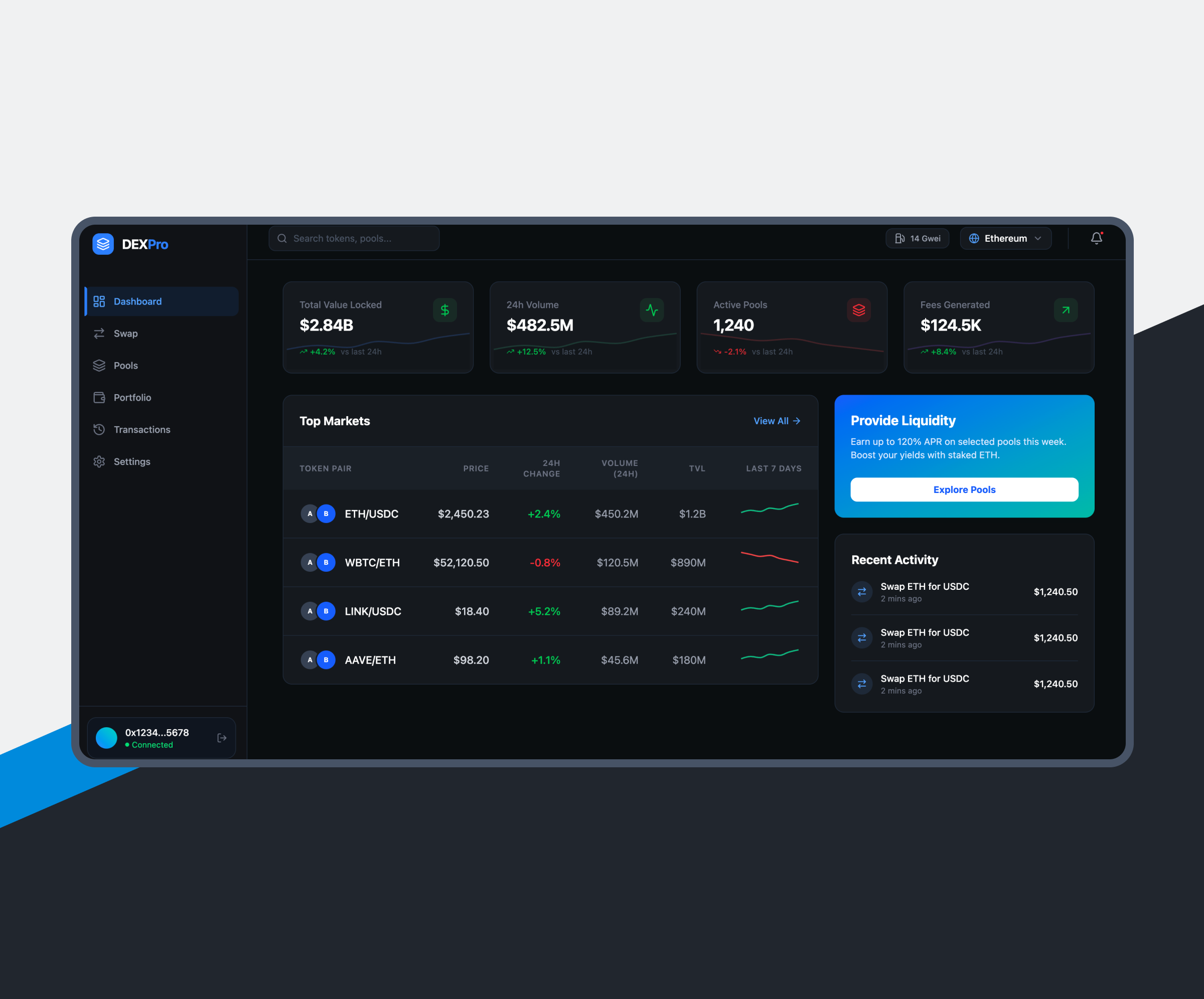

Data Pipeline
Automation Services
What Challenges We Solve with Data Pipeline Automation Services

Data Silos and Fragmented Systems
Fragmented data across systems slows down unified reporting. We build automated connectors and pipelines to centralize data, ensuring consistent, real-time access and fast analytics.

ETL/ELT Failures and Unreliable Workflows
ETL and ELT processes often fail due to schema changes, API limits, or data spikes. Our specialists implement automated retry logic, validation, and orchestration to ensure reliable pipeline execution.

Poor Data Quality and Inconsistency
Poor data quality leads to inconsistent reporting, duplicates, and incorrect insights. We apply automated cleansing, deduplication, and validation rules across pipelines.

Real-time Processing Delays
High latency in data processing delays analytics and decision-making. Elinext designs streaming pipelines and event-driven architecture to deliver near real-time data flow and insights.

Scalability Limitations under Growing Data Loads
Growing data volumes strain pipelines, causing slow processing and failures. We provide distributed architecture and autoscaling to handle increasing load efficiently.

Lack of Monitoring and Governance
Lack of visibility in pipelines leads to unnoticed failures and compliance risks. Elinext ensures monitoring, logging, and governance to ensure reliability and audit readiness.
-
 Data Silos and Fragmented Systems
Data Silos and Fragmented SystemsFragmented data across systems slows down unified reporting. We build automated connectors and pipelines to centralize data, ensuring consistent, real-time access and fast analytics.
-
ETL and ELT processes often fail due to schema changes, API limits, or data spikes. Our specialists implement automated retry logic, validation, and orchestration to ensure reliable pipeline execution.
-
Poor Data Quality and Inconsistency
Poor data quality leads to inconsistent reporting, duplicates, and incorrect insights. We apply automated cleansing, deduplication, and validation rules across pipelines.
-
Real-time Processing Delays
High latency in data processing delays analytics and decision-making. Elinext designs streaming pipelines and event-driven architecture to deliver near real-time data flow and insights.
-
Scalability Limitations under Growing Data Loads
Growing data volumes strain pipelines, causing slow processing and failures. We provide distributed architecture and autoscaling to handle increasing load efficiently.
-
Lack of Monitoring and Governance
Lack of visibility in pipelines leads to unnoticed failures and compliance risks. Elinext ensures monitoring, logging, and governance to ensure reliability and audit readiness.


Stop losing time and revenue to slow or unreliable data pipelines
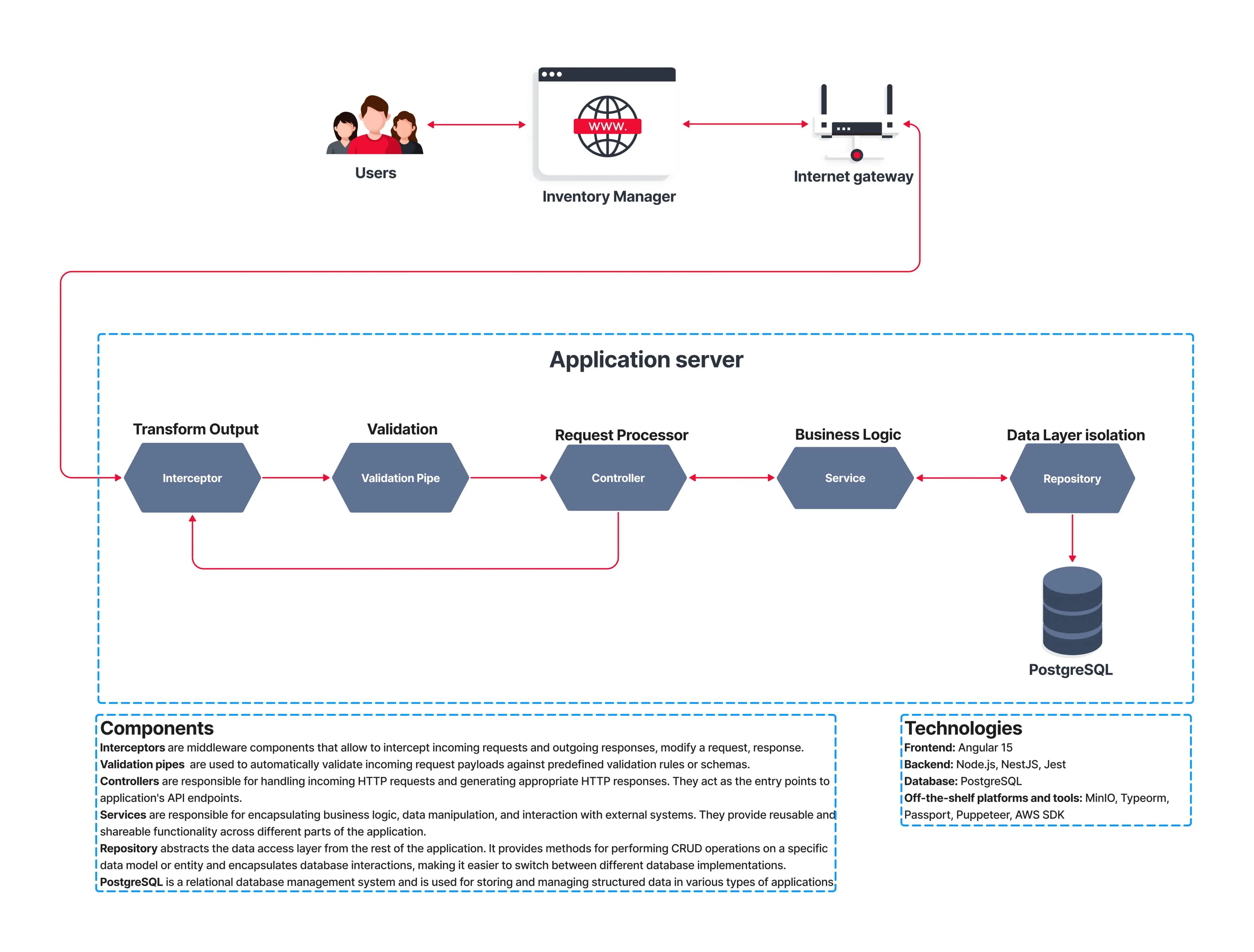
Custom Data Pipeline Automation Services We Offer

Ingestion Automation
Data ingestion automation collects information from databases, APIs, cloud apps, and streaming sources without manual handling. Elinext builds scalable ingestion layers with Kafka, Airbyte, and cloud connectors to reduce synchronization delays and improve data consistency.
ETL/ELT Automation
ETL and ELT automation transform and prepare raw data for analytics and operational systems. Within Elinext data pipeline automation services, our engineers automate transformations with Spark, dbt, Airflow, and cloud-native processing pipelines to reduce repetitive engineering work.

Real-time Data Automation
Real-time pipelines process events immediately instead of waiting for scheduled batch jobs. We implement streaming architectures with Kafka, Flink, Spark Streaming, and cloud event systems to support low-latency analytics and operational monitoring.

CI/CD for Data Pipelines
Data pipelines require version control and deployment stability just like software applications. Elinext builds CI/CD environments for pipeline testing, rollback management, schema validation, and automated deployment using GitHub Actions, Jenkins, and Terraform.

Monitoring & Alerting Automation
Pipeline failures often remain unnoticed until reporting or operational systems break. We configure automated monitoring with Prometheus, Grafana, Datadog, and cloud observability tools to track latency, schema drift, failures, and throughput anomalies.

Cloud Data Pipeline Automation
Cloud environments require scalable orchestration and distributed processing. Using AWS, Azure, and Google Cloud infrastructure, our team automates data movement across storage, compute, analytics, and streaming services while optimizing operational cost.

Data Quality & Validation Automation
Poor data quality directly affects reporting and AI models. Elinext automates validation rules, anomaly detection, schema verification, and duplicate control using Great Expectations, dbt tests, and custom validation frameworks.

Orchestration & Workflow Automation
Complex pipelines involve dependencies between multiple services, jobs, and environments. Within data pipeline automation solutions, we implement orchestration logic with Apache Airflow, Prefect, Dagster, and Kubernetes-based workflow scheduling.

Data Governance & Lineage Automation
As pipelines grow, businesses often lose visibility into where data originates and how it changes. We build automated lineage tracking, metadata management, and governance systems that improve compliance, auditability, and operational transparency.
-
Ingestion Automation
Data ingestion automation collects information from databases, APIs, cloud apps, and streaming sources without manual handling. Elinext builds scalable ingestion layers with Kafka, Airbyte, and cloud connectors to reduce synchronization delays and improve data consistency.
-
ETL and ELT automation transform and prepare raw data for analytics and operational systems. Within Elinext data pipeline automation services, our engineers automate transformations with Spark, dbt, Airflow, and cloud-native processing pipelines to reduce repetitive engineering work.
-
Real-time Data Automation
Real-time pipelines process events immediately instead of waiting for scheduled batch jobs. We implement streaming architectures with Kafka, Flink, Spark Streaming, and cloud event systems to support low-latency analytics and operational monitoring.
-
CI/CD for Data Pipelines
Data pipelines require version control and deployment stability just like software applications. Elinext builds CI/CD environments for pipeline testing, rollback management, schema validation, and automated deployment using GitHub Actions, Jenkins, and Terraform.
-
Monitoring & Alerting Automation
Pipeline failures often remain unnoticed until reporting or operational systems break. We configure automated monitoring with Prometheus, Grafana, Datadog, and cloud observability tools to track latency, schema drift, failures, and throughput anomalies.
-
Cloud environments require scalable orchestration and distributed processing. Using AWS, Azure, and Google Cloud infrastructure, our team automates data movement across storage, compute, analytics, and streaming services while optimizing operational cost.
-
Data Quality & Validation Automation
Poor data quality directly affects reporting and AI models. Elinext automates validation rules, anomaly detection, schema verification, and duplicate control using Great Expectations, dbt tests, and custom validation frameworks.
-
Orchestration & Workflow Automation
Complex pipelines involve dependencies between multiple services, jobs, and environments. Within data pipeline automation solutions, we implement orchestration logic with Apache Airflow, Prefect, Dagster, and Kubernetes-based workflow scheduling.
-
As pipelines grow, businesses often lose visibility into where data originates and how it changes. We build automated lineage tracking, metadata management, and governance systems that improve compliance, auditability, and operational transparency.
Our Awards and Recognitions



























What Our Experts Say


Choose Your Service Option
Leverage data pipeline automation expertise
Hire a dedicated data engineers
Let us handle your data pipeline automation project
Types of Data Pipeline
Automation Services

Batch Data Pipeline
Batch pipelines process large volumes of data on a schedule instead of continuously. They are commonly used for reporting, backups, and historical analytics where immediate processing is not required and operational cost efficiency matters.

Real-time Streaming
Streaming pipelines move and process events with minimal latency using Kafka, Flink, Spark Streaming, or cloud-native event systems. Within data pipeline automation services, we build architectures that support live analytics, monitoring, fraud detection, and IoT processing.

ML Pipelines
Machine learning pipelines automate data preparation, feature engineering, training, and model deployment. Elinext develops ML workflows with Kubeflow, MLflow, Airflow, and cloud AI services to reduce manual retraining and improve model consistency.

Cloud Native
Cloud-native pipelines use distributed storage, serverless processing, and managed orchestration platforms. We build scalable infrastructures on AWS, Azure, and Google Cloud that automatically adjust compute resources based on workload demand.
ETL/ELT
ETL and ELT pipelines automate extraction, transformation, and loading of structured and unstructured data. Using dbt, Spark, Snowflake, BigQuery, and orchestration tools, our engineers simplify analytics preparation and reduce manual data handling.

Hybrid
Hybrid pipelines combine on-premise infrastructure with cloud environments when data residency, compliance, or legacy systems limit full migration. Within data pipeline automation solutions, Elinext synchronizes workloads across multiple environments while maintaining centralized orchestration and monitoring.
-
Batch Data Pipeline
Batch pipelines process large volumes of data on a schedule instead of continuously. They are commonly used for reporting, backups, and historical analytics where immediate processing is not required and operational cost efficiency matters.
-
Real-time Streaming
Streaming pipelines move and process events with minimal latency using Kafka, Flink, Spark Streaming, or cloud-native event systems. Within data pipeline automation services, we build architectures that support live analytics, monitoring, fraud detection, and IoT processing.
-
Machine learning pipelines automate data preparation, feature engineering, training, and model deployment. Elinext develops ML workflows with Kubeflow, MLflow, Airflow, and cloud AI services to reduce manual retraining and improve model consistency.
-
Cloud-native pipelines use distributed storage, serverless processing, and managed orchestration platforms. We build scalable infrastructures on AWS, Azure, and Google Cloud that automatically adjust compute resources based on workload demand.
-
ETL and ELT pipelines automate extraction, transformation, and loading of structured and unstructured data. Using dbt, Spark, Snowflake, BigQuery, and orchestration tools, our engineers simplify analytics preparation and reduce manual data handling.
-
Hybrid
Hybrid pipelines combine on-premise infrastructure with cloud environments when data residency, compliance, or legacy systems limit full migration. Within data pipeline automation solutions, Elinext synchronizes workloads across multiple environments while maintaining centralized orchestration and monitoring.

Artificial Intelligence Solutions for Data Pipeline Automation
…
Our Automated Data Pipeline Advantages

Seamless Scalability
Scalable pipelines automatically adapt to growing workloads without major architecture redesign. Our engineers use distributed processing, Kubernetes orchestration, and cloud-native scaling to maintain stable throughput during traffic spikes and large ingestion volumes.

Accelerated Insights
Slow pipelines delay reporting, forecasting, and operational response. Within data pipeline automation services, Elinext builds streaming and parallel-processing architectures that reduce analytics latency and improve access to near real-time business data.

Reduced Compliance Risks
Regulated industries require traceable data movement and controlled access. We implement lineage tracking, audit logging, schema governance, and automated retention policies that simplify compliance management across distributed systems.

Enhanced Data Accuracy
Data inconsistencies often appear during ingestion, transformation, or synchronization between platforms. Our automation layers validate schemas, detect anomalies, remove duplicates, and enforce transformation rules before data reaches analytics environments.

Greater Operational Efficiency
Manual data handling consumes engineering resources and increases operational overhead. Using data pipeline automation solutions, Elinext automates scheduling, orchestration, monitoring, and recovery workflows to reduce repetitive maintenance tasks.

Enablement of AI & Advanced Analytics
AI models require stable, validated, and continuously updated datasets. We design pipelines optimized for feature processing, real-time ingestion, and scalable data delivery that support machine learning and advanced analytics environments.
-
Seamless Scalability
Scalable pipelines automatically adapt to growing workloads without major architecture redesign. Our engineers use distributed processing, Kubernetes orchestration, and cloud-native scaling to maintain stable throughput during traffic spikes and large ingestion volumes.
-
Accelerated Insights
Slow pipelines delay reporting, forecasting, and operational response. Within data pipeline automation services, Elinext builds streaming and parallel-processing architectures that reduce analytics latency and improve access to near real-time business data.
-
Reduced Compliance Risks
Regulated industries require traceable data movement and controlled access. We implement lineage tracking, audit logging, schema governance, and automated retention policies that simplify compliance management across distributed systems.
-
Enhanced Data Accuracy
Data inconsistencies often appear during ingestion, transformation, or synchronization between platforms. Our automation layers validate schemas, detect anomalies, remove duplicates, and enforce transformation rules before data reaches analytics environments.
-
Greater Operational Efficiency
Manual data handling consumes engineering resources and increases operational overhead. Using data pipeline automation solutions, Elinext automates scheduling, orchestration, monitoring, and recovery workflows to reduce repetitive maintenance tasks.
-
Enablement of AI & Advanced Analytics
AI models require stable, validated, and continuously updated datasets. We design pipelines optimized for feature processing, real-time ingestion, and scalable data delivery that support machine learning and advanced analytics environments.
The Benefits of Data Pipeline
Automation Services by Elinext

Key Steps in Our Data Pipeline Automation Process

Consulting and Assessment
We start by analyzing data sources, processing volumes, infrastructure limitations, and reporting dependencies. This helps identify bottlenecks, unstable workflows, and integration risks before automation architecture is designed.

Architecture Design
Pipeline architecture defines how data moves, scales, and recovers from failures. Our engineers design distributed processing, orchestration, storage, and streaming layers optimized for cloud, hybrid, or on-premise environments.

Implementation and Automation
At this stage, we automate ingestion, scheduling, synchronization, and data movement between systems. Elinext implements orchestration with Airflow, Prefect, Kafka, Spark, and cloud-native automation services.

Transformation and Quality Layer
Raw data rarely arrives in a consistent format. We build transformation and validation layers with schema checks, deduplication, anomaly detection, and business rules to improve data reliability before analytics processing.

Testing and Validation
Pipeline testing verifies stability under real workloads and schema changes. Our team validates transformations, latency, recovery logic, throughput limits, and dependency handling before production deployment begins.
Monitoring and Optimization
After deployment, pipelines require continuous monitoring to detect failures, latency spikes, and infrastructure inefficiencies. We configure observability systems, alerts, and performance optimization workflows to maintain long-term stability.
-
Consulting and Assessment
We start by analyzing data sources, processing volumes, infrastructure limitations, and reporting dependencies. This helps identify bottlenecks, unstable workflows, and integration risks before automation architecture is designed.
-
Pipeline architecture defines how data moves, scales, and recovers from failures. Our engineers design distributed processing, orchestration, storage, and streaming layers optimized for cloud, hybrid, or on-premise environments.
-
Implementation and Automation
At this stage, we automate ingestion, scheduling, synchronization, and data movement between systems. Elinext implements orchestration with Airflow, Prefect, Kafka, Spark, and cloud-native automation services.
-
Transformation and Quality Layer
Raw data rarely arrives in a consistent format. We build transformation and validation layers with schema checks, deduplication, anomaly detection, and business rules to improve data reliability before analytics processing.
-
Pipeline testing verifies stability under real workloads and schema changes. Our team validates transformations, latency, recovery logic, throughput limits, and dependency handling before production deployment begins.
-
Monitoring and Optimization
After deployment, pipelines require continuous monitoring to detect failures, latency spikes, and infrastructure inefficiencies. We configure observability systems, alerts, and performance optimization workflows to maintain long-term stability.
Hire Data Engineers from Elinext









Industries We Serve











What Our Customers Think















FAQ
-
Data pipeline automation includes data ingestion, transformation, synchronization, and delivery between systems. They help businesses reduce manual processing, improve reporting reliability, and support scalable analytics environments.
-
Data pipeline automation uses orchestration tools, workflows, and processing engines to move and transform data automatically between sources, storage, and analytics systems with minimal manual intervention.
-
Automated pipelines reduce operational overhead, improve processing speed, and minimize human error. Businesses use them to deliver analytics faster, maintain data consistency, and support growing workloads more efficiently.
-
Automation improves data quality through schema validation, anomaly detection, deduplication, and transformation rules applied during processing. This helps prevent inaccurate or incomplete data from reaching reporting systems.
-
Real-time pipeline automation is designed for low-latency processing of streaming events and live operational data. It is commonly used in monitoring systems, fraud detection, IoT environments, and customer analytics platforms.
-
Automated pipelines use encryption, role-based access control, audit logging, and monitoring systems to secure data movement and processing. Security configuration depends on infrastructure, compliance needs, and processing environments.
-
Implementation time depends on pipeline complexity, integrations, cloud architecture, and data volume. Smaller automation projects may take weeks, while enterprise-scale distributed environments can require several months.
-
The cost depends on infrastructure scale, processing complexity, orchestration requirements, cloud usage, and real-time processing needs. Streaming and distributed architectures usually require larger implementation scope.



















{kind=link}
{kind=link}