

This blog post follows up on CI/CD optimization for infrastructure solutions provider case study. We will cover the how-to of optimizing our Jenkins pipelines with shared libraries, and provide examples for a simple maven+podman build.
While we will be focusing on Declarative Pipelines in this post, keep in mind that both declarative and scripted pipelines can make use of shared libraries. Most of the concepts covered here will also apply to scripted pipelines, but they will vary in some cases.
Benefits of using shared libraries
Using shared libraries in Jenkins comes with multiple benefits, similar to using libraries for other programming languages. Here we’ve highlighted five major benefits:
- Reusing code: Oftentimes pipelines written across multiple jobs will end up nearly identical, with the only real difference being a couple of variables like project name, or version – with a shared library we can use the same piece of code, eliminating unnecessary redundancy
- Easier maintenance: this ties into the previous point, as centralizing code within a shared library makes code changes quicker and easier. Jobs will pull changes from the library periodically; alternatively, you can set the library to automatically pull the updated shared library code for every build, propagating our changes immediately
- Standardization: shared libraries make the enforcement of better coding standards easier, allowing us to implement a standard user interface for configuration of jobs, set up quality gates, and various other tasks without making individual jobs harder to configure
- Safer jobs: with a well-crafted shared library, we can implement all the necessary checks for inputs to avoid potential vulnerabilities, assist in debugging, or recover from certain errors
- Streamlined pipeline code: with a shared library abstracting the inner workings of various functions in our code, we can have a high level of complexity within our pipelines while only exposing a streamlined interface to the build engineer
Premise
For our example implementation, we’ll use 3 different languages (Java, Rust, and Go) spread across 12 jobs. Each job needs all of its steps written out separately; fetching code, running tests, building, etc. Most of these steps reuse a lot of code, even when building for different languages.
For simplicity’s sake, we’ll omit parameters, and we will only include the following stages:
- Fetching code (git)
- Building (maven)
- Building container (podman)
- Pushing container to registry (on-premises registry)
Here’s an example of said simple Pipeline:
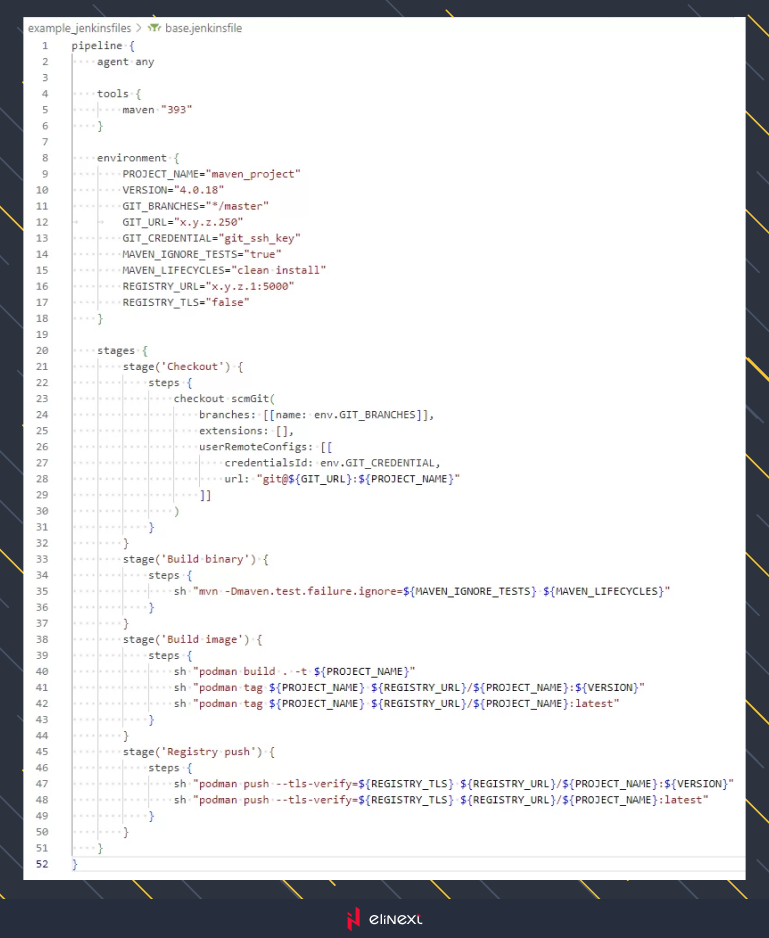
You’ll find that all of our variables are already exported into the environment block, while most of the code in the stages block can be safely moved into a shared library. From there, we can simply call it from within the pipeline.
Implementation
Firstly, let’s add our shared library to Jenkins so that we can call it in our pipelines. (You’ll need administrator access to configure this on your Jenkins controller.)
- Navigate to your Jenkins dashboard and click “Manage Jenkins” on the left panel, then choose “System”, alternatively, you can navigate directly to this path: /manage/configure
- Scroll down to “Global Pipeline Libraries” and click on the “Add” button
- Fill out all the necessary parameters. Please note that shared libraries require the use of an SCM like git
We would also recommend checking “Fresh clone per build” while testing, so any library changes are immediately reflected in your jobs.
For our example, we’ve also decided to use hash maps to hold our different options, but if you want to use, e.g. environment variables, you can do that too, however, you would need to change the input for your library methods.
Here’s our example pipeline using a shared library:
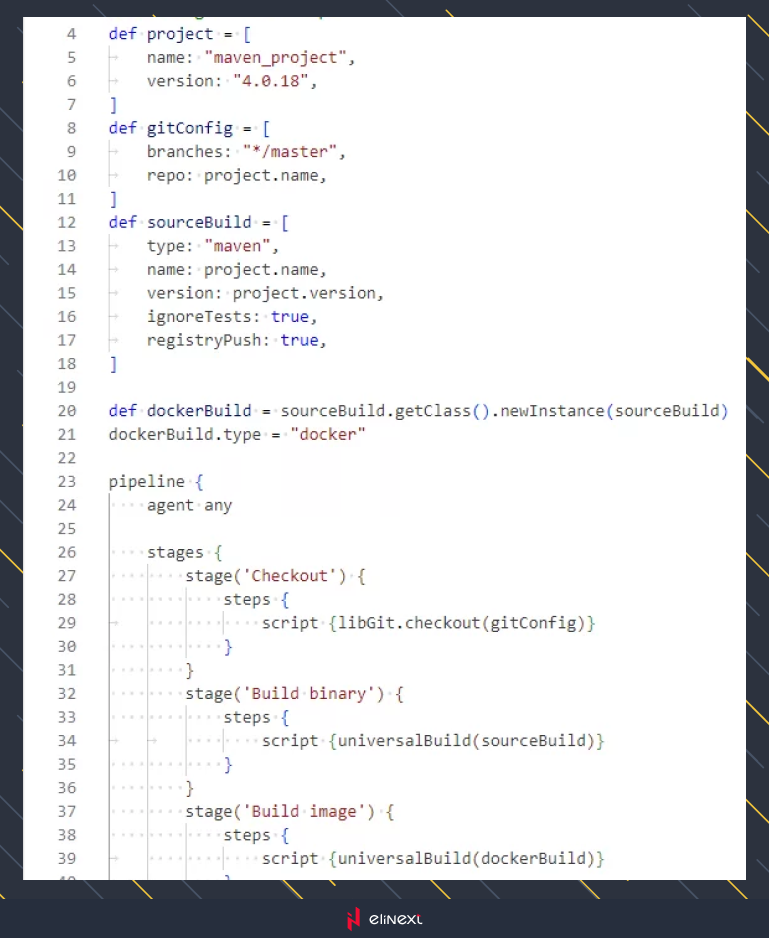
We are now able to remove some of the previous variables, they are now stored within the shared library, but we still can overwrite them, for example, dockerBuild.registryURL. The tools block was also removed as it’s now called whenever we run universalBuild() with a maven build type.
In a more elaborate implementation, we could detect the type of build from context, or even parse the relevant configuration file to get the version string (e.g. pom.xml for maven). All of this can be abstracted within the universalBuild() function. We can even move the entire pipeline into a shared library, however, we won’t be covering this today.
Note: we need to place our function calls into a script block, if we’re using declarative pipelines.
Let’s look at what is inside universalBuild():
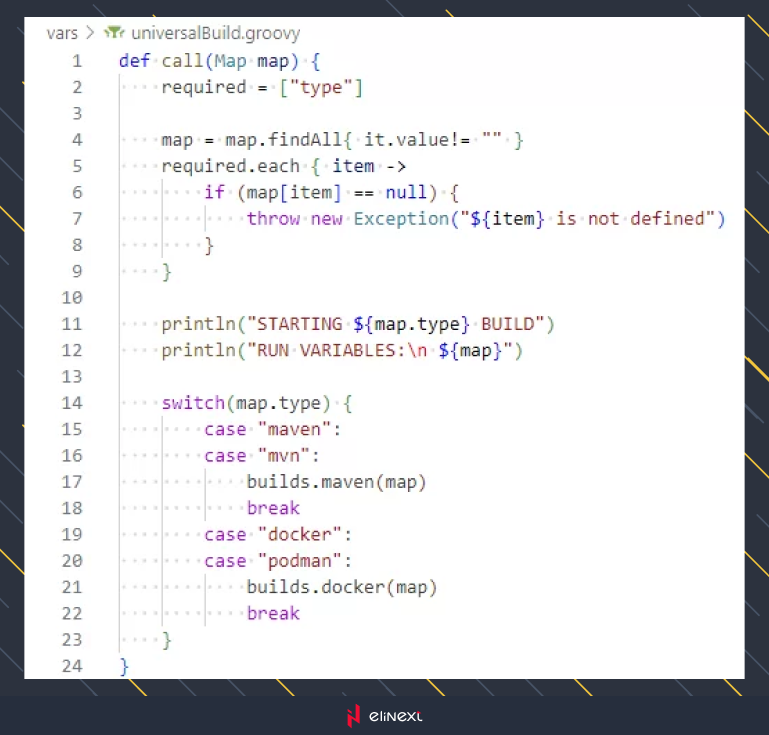
What is inside universalBuild
Link to code
This is a straightforward function that does some preprocessing before calling the relevant build function, now let’s look at builds.maven() next.
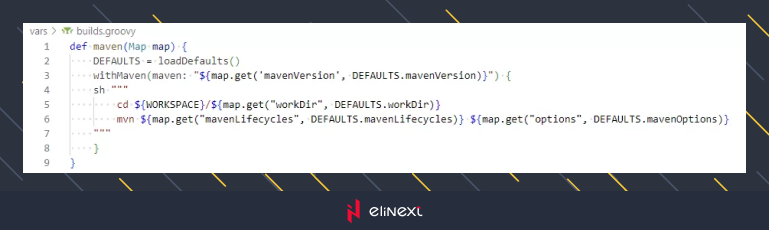
It’s also a very simple function that just calls some defaults, loads the relevant Maven version, and lastly builds with Maven.
(The rest of the functions, like gitLib.checkout() or builds.docker() are available in the repository linked at the bottom of the post and under any of the images.)
Conclusion
Shared libraries offer numerous advantages, and the earlier you implement them with your team, the more use you’ll get out of them. With a scalable and easy-to-use shared library, your team can focus on matters other than constant job maintenance and not worry about not meeting certain standards set by your company, as they can be checked within the library. In summary, shared libraries are a very powerful tool within Jenkins that any medium to large team should make use of to both save on engineer hours and make their CI/CD process rock solid!
Extra resources
- Shared library example – Repository containing all of the code shared in this post
- Shared Libraries Docs – Official Jenkins Shared Library documentation
- CloudBeesTV – High-quality Jenkins tutorial videos
- Online Groovy Sandbox – Test out parts of your scripts before implementing them into your pipeline.
