

AutoML solutions use advanced AutoML platform and MLOps services and solutions to automate machine learning workflows, from data preprocessing to deployment. Designed for data scientists, business analysts, and enterprises, these tools accelerate model development, reduce costs, and improve productivity. Siemens uses AutoML for predictive maintenance, and PayPal for fraud detection. Users get faster and more accurate results with less manual effort, making AI accessible to a wider audience.
By 2026, AutoML software and AutoML solutions supported by ML development services will reduce model development time by 80%. With a market size of $4.7 billion and a 40% increase in productivity, companies like Walmart predict faster demand growth.
Automated Machine Learning (AutoML) tackles the challenge of making machine learning more accessible by simplifying the intricate process of model development. With its applications spanning various industries, AutoML solutions strive to enable those without specialized knowledge to utilize machine learning effectively. The article underscores the increasing importance and adoption of machine learning across different sectors through the use of Automated Machine Learning (AutoML).
How AutoML Works?
AutoML software automates model selection, feature engineering, and tuning. Unlike MLOps, which manages deployment, AutoML focuses on model building—for example, AutoML vs. MLOps: AutoML builds, MLOps deploys.
Automated Machine Learning (AutoML) is a technology designed to automate the end-to-end process of applying machine learning to real-world problems. Its purpose is to make machine learning accessible to non-experts and to improve the efficiency of experts by automating repetitive tasks such as data preprocessing, featurization, algorithm selection, hyperparameter tuning, ensemble modeling, and MLOps. A range of tools and AI software development services exists to automate these processes. Some notable examples include Auto Sklearn, Auto-PyTorch, AutoKeras, Google AutoML, and H2O.ai, among others. The aim of this article is to overview these key components of AutoML and give examples of real cases.
Improve efficiency with AutoML solutions and smart manufacturing solutions and ensure your business resilience today. Elinext’s article on tech trends that are shaping our future provides context on the broader forces driving digitalisation across industries — from AI adoption and edge computing to the changing economics of software delivery — offering a useful frame for understanding where specific technology investments fit into the wider market trajectory.
What is the main idea of AutoML?
AutoML speeds up the creation and implementation of machine learning models. This efficiency not only saves time and resources but also allows experts to focus on more strategic and innovative aspects of their projects. The potential impact of AutoML solutions is vast, as it can drive advancements across various industries, from healthcare and finance to retail and manufacturing, by enabling faster and more accurate decision-making processes. Ultimately, AutoML solutions have the potential to transform how organizations leverage data, fostering innovation and improving outcomes on a global scale.
Data preprocessing
Data preprocessing is an essential phase in the machine learning workflow. It involves transforming raw data into a clean and usable format, which significantly impacts the performance of machine learning models. AutoML platforms automate many aspects of the machine learning process, including data preprocessing. Here’s how AutoML typically handles key preprocessing tasks:
Handling Missing Values:
Imputation: AutoML tools can automatically fill in missing values using techniques like mean, median, or mode imputation, or more advanced methods like k-nearest neighbors (KNN) imputation.
Deletion: In some cases, AutoML might remove rows or columns with a high percentage of missing values.
Scaling Features:
Normalization: AutoML can normalize features to a range, typically [0, 1], which is useful for algorithms that require normalized data.
Standardization: It can also standardize features to have a mean of 0 and a standard deviation of 1, which is important for algorithms like SVM and logistic regression.
Encoding Variables:
Label Encoding: AutoML can convert categorical variables into numerical values by assigning a unique integer to each category.
One-Hot Encoding: It can also create binary columns for each category, which is useful for algorithms that cannot handle categorical data directly.
In practice, for implementing this step, there are lots of instruments. To cite one example, the YData Profiling package has gained wide popularity for this purpose. YData Profiling is used in AutoML to implement the data preprocessing phase by providing detailed insights into the dataset before model training begins. By automating these preprocessing steps, AutoML makes it easier for users to build robust machine learning models without needing deep expertise in data science. This not only saves time but also ensures that best practices are consistently applied.
Featurization
AutoML automates the extraction of useful features from raw data through a process known as featurization. This involves several key steps to transform raw data into a format that machine learning models can effectively use:
Data Scaling and Normalization:
AutoML applies scaling and normalization techniques to ensure that features are on a comparable scale. This is crucial for algorithms that are sensitive to the scale of input data.
Handling Missing Values:
AutoML identifies and addresses missing values using imputation methods, such as filling in gaps with the mean, median, or employing more advanced techniques.
Encoding Categorical Variables:
Categorical data is converted into numerical format using techniques like one-hot encoding or label encoding. This allows machine learning algorithms to process categorical data effectively.
Feature Generation:
AutoML can create new features from existing data. For example, it might generate polynomial features or interaction terms that capture relationships between variables.
Dimensionality Reduction:
Techniques like Principal Component Analysis (PCA) or feature selection methods are used to reduce the number of features while retaining the most important information. This helps in improving model performance and reducing computational complexity.
Text and Image Processing:
For text data, AutoML can perform tasks like tokenization, stemming, and converting text to numerical vectors using methods like TF-IDF or word embeddings. For image data, it can extract features using convolutional neural networks (CNNs) or other image processing techniques.
By automating these steps, AutoML ensures that the data is well-prepared for model training, reducing the need for extensive manual feature engineering and allowing data scientists to focus on higher-level tasks.
Algorithm selection
In AutoML, the process of choosing appropriate algorithms begins with identifying the type of machine learning problem, such as classification, regression or clustering. Based on this, AutoML selects a set of candidate algorithms that are well-suited for the task. For instance, for a classification problem, it might consider algorithms like logistic regression, decision trees, random forests, support vector machines (SVM), and neural networks. The system then preprocesses the data to ensure it is clean and ready for training. Multiple models are trained using these algorithms, often employing cross-validation to ensure robust evaluation. During this phase, hyperparameters are also tuned to find the optimal settings for each algorithm. The performance of each model is evaluated using appropriate metrics, and ensemble techniques like bagging, boosting, or stacking may be applied to further enhance accuracy. Finally, the best-performing model or ensemble of models is selected based on the evaluation metrics, ready for deployment.
Hyperparameter tuning
In machine learning, a hyperparameter is a configuration that is set before the learning process begins and controls the behavior of the training algorithm. Unlike model parameters, which are learned from the data during training, hyperparameters are specified by the practitioner and can significantly influence the performance of the model. Hyperparameter tuning is a critical component of AutoML, as it optimizes the settings that control the learning process of machine learning models. Here’s how AutoML handles hyperparameter tuning:
Automated Search:
AutoML platforms use various algorithms to automatically search for the best hyperparameters. Techniques like grid search, random search, and more advanced methods like Bayesian optimization are commonly employed.
Bayesian Optimization:
This method is particularly popular in AutoML for hyperparameter tuning. It uses a probabilistic model to predict the performance of different hyperparameter settings and iteratively selects the most promising ones to evaluate.
Multi-Fidelity Methods:
These methods evaluate hyperparameters using cheaper approximations of the target function, such as training on a subset of the data or for fewer epochs. This allows for quicker assessments and helps in narrowing down the best hyperparameters more efficiently.
Combined Algorithm Selection and Hyperparameter Optimization (CASH):
AutoML systems often need to select not only the best hyperparameters but also the best model. CASH treats this as a single optimization problem, where the algorithm choice and its hyperparameters are optimized together.
Scalability:
AutoML platforms leverage distributed computing to scale hyperparameter tuning across multiple machines, speeding up the process and enabling the handling of large datasets and complex models.
Ensemble Modeling
AutoML combines multiple models to improve accuracy through a technique known as ensemble learning. This approach leverages the strengths of different models to create a more robust and accurate predictive system. Here are some key methods AutoML uses to combine models:
Bagging (Bootstrap Aggregating):
AutoML trains multiple instances of a base model on different subsets of the data and averages their predictions. This reduces variance and helps in creating a more stable and accurate model.
Boosting:
This method sequentially trains models, where each new model focuses on correcting the errors made by the previous ones. By integrating these models, AutoML can greatly enhance overall accuracy and minimize bias.
Stacking:
AutoML uses stacking to train multiple base models and then combines their predictions using a meta-model. The meta-model learns to make the final prediction based on the outputs of the base models, effectively capturing the strengths of each individual model.
Voting:
This straightforward ensemble technique involves AutoML merging the predictions of several models by either taking a majority vote for classification tasks or averaging for regression tasks. This helps in balancing out the weaknesses of individual models.
Examples of real-world applications using AutoML:
Case Study 1:
California Design Den, a home textiles company, aimed to improve its demand forecasting to optimize inventory management and reduce stockouts and overstock situations. The company needed to accurately predict demand for various products across different regions and seasons, which required analyzing a large and complex dataset.
Solution: California Design Den utilized AutoML to automate the demand forecasting process, leveraging its capabilities to handle data preprocessing, model selection, and hyperparameter tuning.
Outcome: By using AutoML, California Design Den achieved more accurate demand forecasts, which led to better inventory management. This resulted in reduced stockouts and overstock situations, ultimately improving customer satisfaction and reducing costs.
Case Study 2:
Zillow, an online real estate marketplace, aimed to improve the accuracy of its Zestimate home value prediction tool to provide more reliable property valuations. The company needed to analyze a vast and diverse dataset, including property features, historical sales data, and market trends, to predict home values accurately.
Solution: Zillow utilized AutoML to automate the model development process, leveraging its capabilities to handle data preprocessing, feature engineering, model selection, and hyperparameter tuning.
Outcome: By using AutoML, Zillow significantly improved the accuracy of its Zestimate tool, providing more reliable home value predictions. This enhanced user trust and engagement on the platform, ultimately driving business growth.
Case Study 3:
Mercedes-Benz aimed to optimize its vehicle sensor data analysis to improve predictive maintenance and enhance vehicle performance.The company needed to process and analyze vast amounts of sensor data from its vehicles to predict potential failures and optimize maintenance schedules.
Solution: Mercedes-Benz utilized AutoML to automate the data preprocessing, feature engineering, model selection, and hyperparameter tuning processes.
Outcome: By using AutoML, Mercedes-Benz significantly improved the accuracy of its predictive maintenance models. This led to more efficient maintenance schedules, reduced downtime, and enhanced vehicle performance.
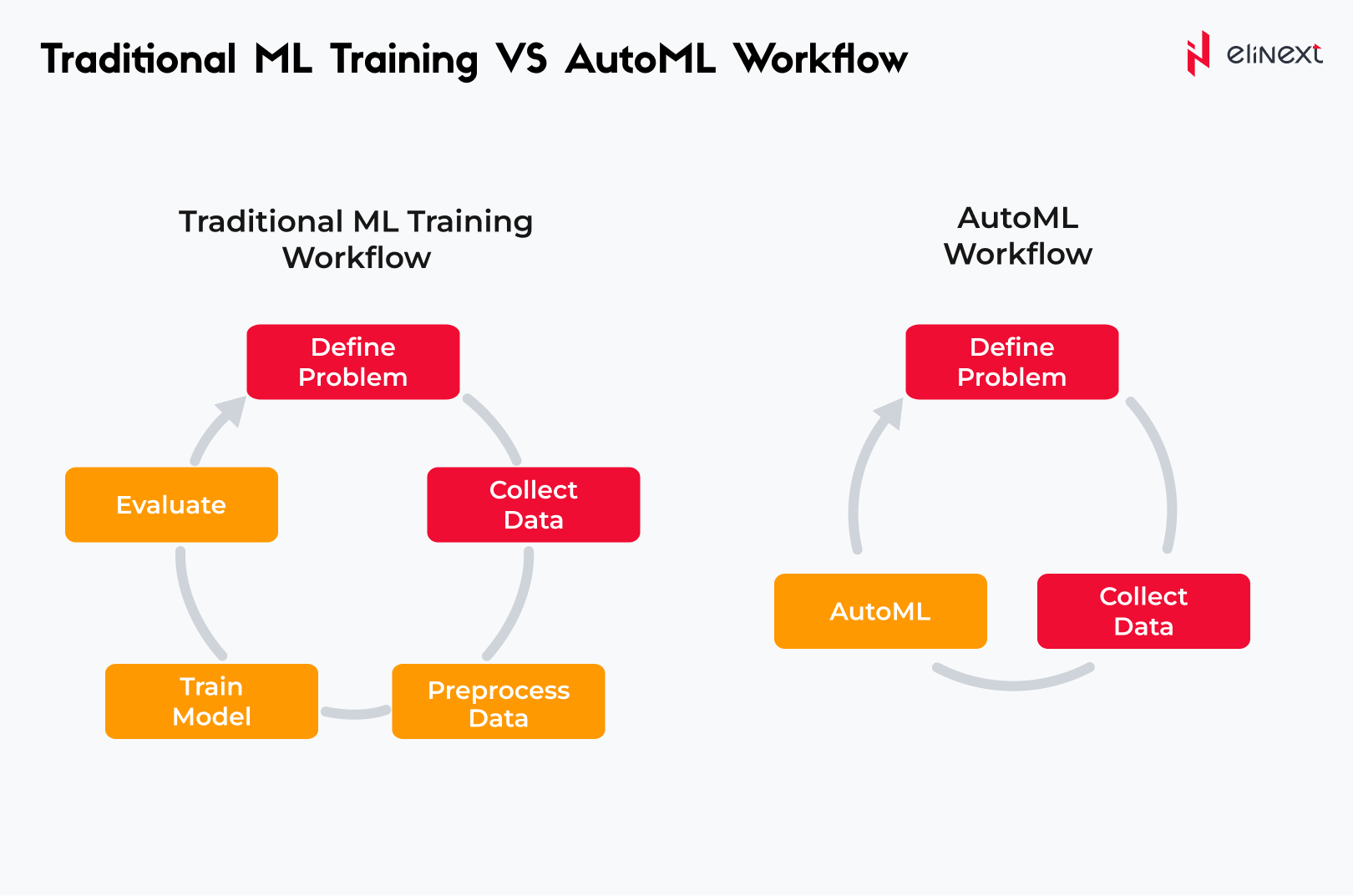
AutoML vs Standard Approach
AutoML (Automated Machine Learning) represents a significant shift from the standard approach to machine learning by automating many of the complex and time-consuming tasks involved in model development. While the standard approach requires extensive manual intervention for data preprocessing, feature engineering, algorithm selection, and hyperparameter tuning, AutoML streamlines these processes, making machine learning more accessible to non-experts. AutoML systems can autonomously manage scale features, missing values, determine the best algorithms, encode categorical variables and hyperparameters using techniques such as grid search and Bayesian optimization.
This not only accelerates the model development process but also often results in models that are as good as or better than those created manually. By reducing the need for deep expertise and manual effort, AutoML allows data scientists to focus on higher-level tasks and innovation, ultimately democratizing the use of the machine learning industry.
AutoML solutions are complex due to data volatility and integration challenges. At Elinext, we bridge AutoML vs MLOps gaps with robust data engineering services and specialized AutoML software, ensuring seamless automation and deployment. This approach reduces errors associated with manual data entry, accelerates delivery, and delivers measurable business impact for our clients.
Elinext Expert
Conclusion
AutoML solutions based on AutoML platform and data science development services are transforming industries. For example, Siemens uses AutoML to predict equipment failures, reducing downtime and costs. The global AutoML market is projected to reach $4.7 billion by 2026, with a CAGR of 44.6%, and enterprises are reporting productivity gains of up to 40%. Considering that only 20% of enterprises are implementing AutoML, there is enormous potential for growth and competitive advantage.
AutoML Solutions: Terms Explained
-
Automated Model Selection
Automated model selection is an AutoML process that tests multiple algorithms on a dataset and automatically selects the best-performing model based on evaluation metrics, saving time and improving accuracy.
-
Feature Engineering Automation
Feature engineering automation uses AutoML to automatically create, select, and transform data features, optimizing input data for model training and reducing the effort required for manual data preparation.
-
Hyperparameter Optimization
Hyperparameter optimization in AutoML automatically finds optimal settings (such as learning rate or tree depth) for each model, using methods such as grid search or Bayesian search to maximize performance.
-
Pipeline Automation
Pipeline automation coordinates the entire machine learning workflow data preprocessing, feature engineering, training, evaluation, and deployment ensuring repeatable, efficient, and error-free processes.
-
Model Evaluation Metrics
Model evaluation metrics are quantitative metrics (e.g., accuracy, F1 score, RMSE) that AutoML uses to evaluate and compare model performance, enabling the selection of the best model for deployment.
-
Neural Architecture Search (NAS)
Neural Architecture Search (NAS) is an AutoML technique that automatically explores and designs optimal neural network architectures for specific tasks, improving the performance of deep learning models.
-
End-to-End ML Pipeline Deployment
End-to-end machine learning pipeline deployment automates moving a trained model to production, configuring output endpoints, monitoring, and enabling retraining for continuous improvement.
FAQ
What is AutoML?
AutoML solutions are platforms that automate the creation, training, and deployment of machine learning models. They are used to simplify complex machine learning tasks, making AI accessible to non-experts. Enterprises use AutoML solutions to accelerate analytics, reduce costs, and improve decision making, as seen in predictive maintenance and fraud detection.
What are AutoML solutions used for?
AutoML solution is an AutoML platform designed to automate the entire machine learning process. They are used for tasks such as predictive maintenance, fraud detection, and demand forecasting. Enterprises use AutoML platforms to build accurate models faster, enabling data-driven decisions without deep machine learning expertise.
What problems does AutoML solve?
AutoML software solves the problem of manual, labor-intensive machine learning development by automating model selection, feature engineering, and tuning. It is used to reduce errors, accelerate analytics, and lower costs. Enterprises use AutoML software to democratize AI, delivering faster and more reliable results across industries.
Does AutoML replace data scientists?
AutoML vs. MLOps: AutoML doesn’t replace data scientists, but it automates repetitive tasks such as model selection and tuning. It is used to improve productivity and free up data scientists for complex analysis. Enterprises use AutoML and MLOps together for efficient, scalable, and reliable machine learning deployment.
What are the main components of AutoML?
AutoML software and AutoML platforms include automated model selection, automated feature engineering, hyperparameter optimization, pipeline automation, model evaluation metrics, neural architecture search, and end-to-end deployment. Companies use them to streamline machine learning workflows and accelerate innovation.
What are the benefits of AutoML solutions?
AutoML solutions are tools that automate machine learning workflows, making AI accessible to non-experts. They are used to reduce development time, lower costs, and improve model accuracy. Enterprises benefit from faster analytics, increased productivity, and the ability to scale AI initiatives across departments.
What industries use AutoML?
AutoML software is used in industries such as healthcare (disease diagnostics), finance (fraud detection), manufacturing (predictive maintenance), and retail (demand forecasting). Enterprises use AutoML software to solve industry-specific problems and gain a competitive advantage.
How does AutoML differ from traditional machine learning?
AutoML solutions and any AutoML platform automate the machine learning workflow, while traditional machine learning requires manual intervention at every stage. AutoML is used for fast and affordable model development; traditional machine learning offers more customization options. Enterprises use AutoML for speed and scalability, while traditional machine learning addresses complex, customized problems.
