

Multimodal learning, which involves the integration of multiple data modalities such as text and images, is a rapidly evolving field in machine learning. This approach leverages the complementary strengths of different data types to improve the performance and capabilities of AI models.
Overview of Multimodal Learning
Humans use their five senses — sight, hearing, touch, taste, and smell — to gather and integrate different types of information. This ability allows us to understand complex situations, such as a conversation, by combining sensory inputs.
AI seeks to mimic this process through Multimodal Deep Learning, which teaches models to process and fuse various types of data for a more complete understanding. This article will cover how multimodal fusion works, the role of multimodal datasets, and the applications of these technologies, explaining how AI models achieve a more holistic view of information.
Multimodal learning combines different types of data to create a more comprehensive and nuanced model. For instance, combining text and image data can significantly improve tasks such as image captioning, visual question answering (VQA), and cross-modal retrieval.
Key Concepts
- Feature Extraction: Extracting meaningful features from both text and images.
- Modality Fusion: Combining the features from different modalities.
- Learning Strategy: Training the model on the combined data.
How does Multimodal Learning work
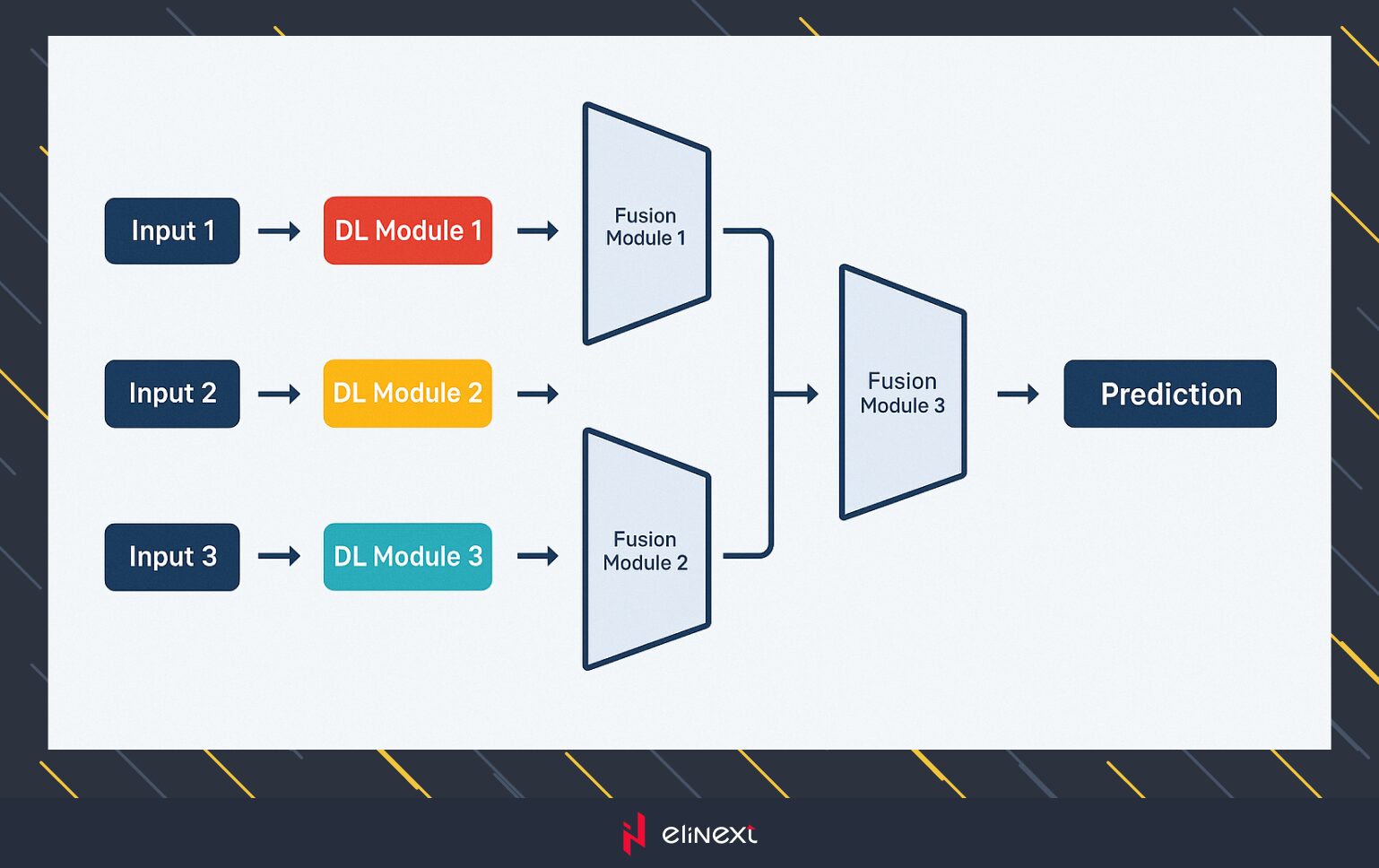
Multimodal neural networks typically combine several unimodal neural networks, each dedicated to processing a different type of data. For instance, an audiovisual model might have one network for visual data and another for audio data. These unimodal networks process their respective inputs separately through a process called encoding. After each modality is encoded, their extracted features are combined using a variety of fusion techniques, ranging from simple concatenation to complex attention mechanisms. This fusion process is critical to the performance of the network.
In essence, multimodal architectures consist of three main components:
Unimodal Encoders: Separate networks for encoding each type of input modality.
Fusion Network: A system that combines the features from each modality after encoding.
Classifier: A network that processes the fused data to make final predictions.
These components are commonly referred to as the encoding module, fusion module, and classification module, respectively.
In a typical multimodal workflow, three unimodal neural networks first independently encode different input modalities. After feature extraction, a fusion module combines these modalities — often merging them in pairs. Finally, the integrated features are fed into a classification network for the final decision-making process.
Multimodal Deep Learning applications
Image Retrieval
Image retrieval involves searching for relevant images within a large database based on a given retrieval key. Also known as Content-Based Image Retrieval (CBIR) or Content-Based Visual Information Retrieval (CBVIR), this task traditionally relies on tag-matching algorithms. However, deep learning multimodal models offer more advanced solutions, reducing the need for manual tagging.
Image retrieval can also be extended to video retrieval. The retrieval key can be a text caption, audio, or even another image, with text descriptions being the most common.
Various cross-modal image retrieval tasks include:
Text-to-Image Retrieval: Finding images that match a textual description.
Text and Image Composition: Modifying a query image based on a textual description.
Cross-View Image Retrieval: Retrieving images from different perspectives or viewpoints.
Sketch-to-Image Retrieval: Finding images that match a hand-drawn pencil sketch.
A practical example of image retrieval is when you use a search engine’s “images” section to view a range of images related to your search query.

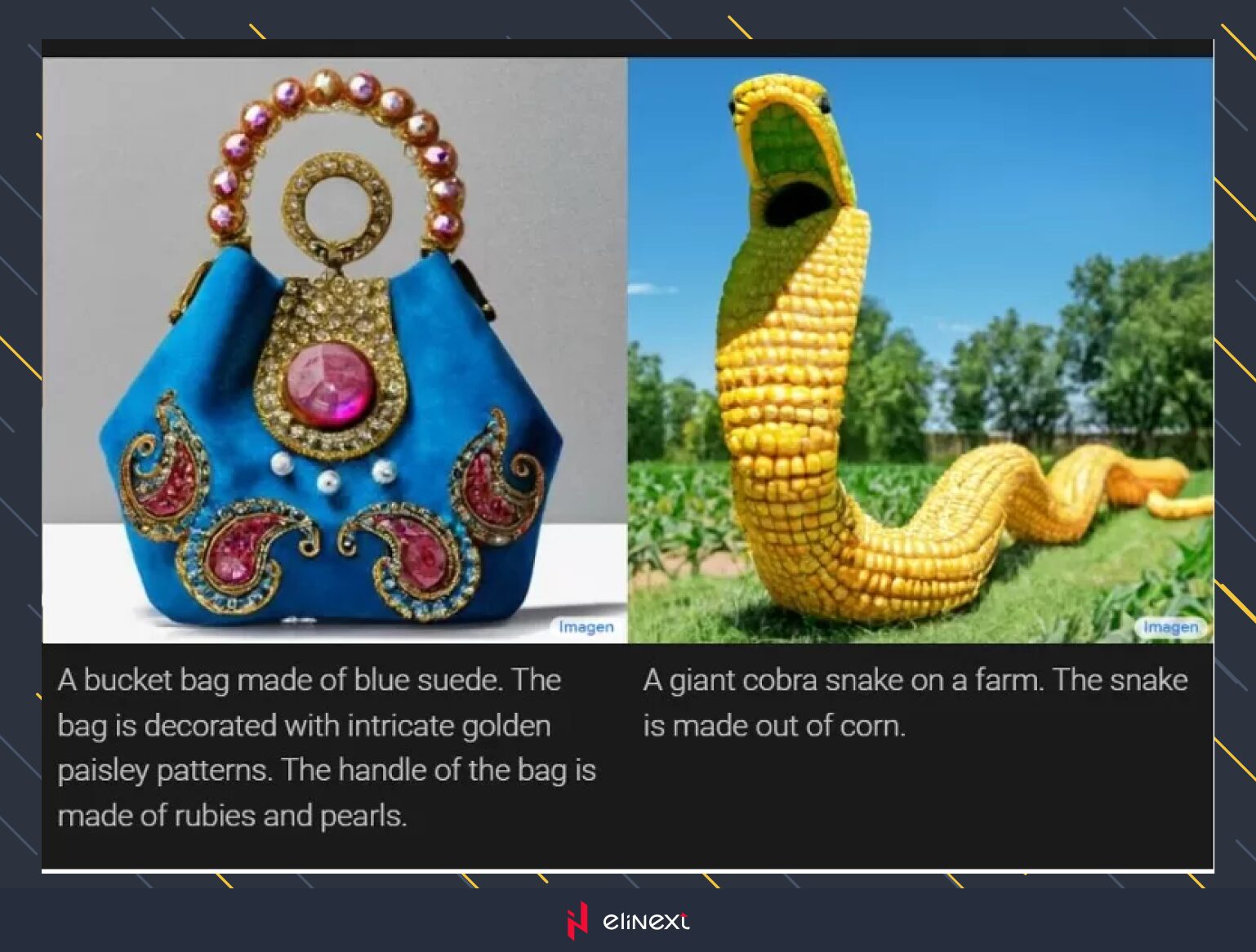
Text-to-Image Generation
Text-to-image generation is a prominent application of multimodal learning, focusing on translating textual descriptions into visual content. Notable models in this area include OpenAI’s DALL-E and Google’s Imagen, which have garnered significant attention for their capabilities.
Unlike image captioning, which involves generating text from images, text-to-image generation creates new images based on textual prompts. Given a brief description, these models generate images that capture the essence and details described in the text. Recently, text-to-video models have also emerged, extending this capability to dynamic visual content.
These technologies are valuable in fields like photo editing, graphic design, and digital art, where they assist in creating visual content and inspire new artistic ideas.
Multimodal Deep Learning Datasets
Multimodal deep learning datasets are crucial for training models that can process and integrate information from multiple types of data sources, such as text, images, audio, and video. These datasets enable AI systems to learn complex relationships between different modalities and improve their performance on tasks that require a comprehensive understanding of diverse data.
- Components of Multimodal Datasets
a. Text Data:
- Sources: Includes documents, social media posts, news articles, and more.
- Formats: Raw text, tokenized text, embeddings.
- Examples: Text descriptions accompanying images, transcripts of audio or video content.
b. Image Data:
- Sources: Photographs, medical images, satellite imagery, and artwork.
- Formats: Pixel values, pre-processed feature vectors.
- Examples: Images paired with descriptive captions or labels.
c. Audio Data:
- Sources: Speech recordings, environmental sounds, music.
- Formats: Waveforms, spectrograms, audio embeddings.
- Examples: Audio clips with corresponding transcripts or emotional labels.
d. Video Data:
- Sources: Recorded video clips from various domains.
- Formats: Frame sequences, temporal feature vectors.
- Examples: Videos with annotated scenes, actions, or dialogues.
- Key Datasets in Multimodal Learning
a. MS COCO (Microsoft Common Objects in Context):
Description: Contains images with detailed object annotations and captions, used for tasks like image captioning and object detection.
Modalities: Images and text.
b. Flickr30k:
Description: Features images paired with multiple descriptive sentences, facilitating tasks such as image-to-text and text-to-image generation.
Modalities: Images and text.
c. VGGSound:
Description: Provides audio-visual data with labeled sound events in videos, useful for audio-visual understanding and action recognition.
Modalities: Video and audio.
d. AVA (Audio-Visual Scene-Aware Dialog):
Description: Combines audio and visual data with dialogues, enabling multimodal tasks like video captioning and scene understanding.
Modalities: Video, audio, and text.
e. LSMDC (Large Scale Movie Description Challenge):
Description: Consists of movie clips with detailed descriptions, useful for video-to-text and text-to-video generation tasks.
Modalities: Video and text.
- Challenges in Multimodal Datasets
a. Data Alignment: Ensuring that different modalities are accurately paired, such as matching images with their corresponding text descriptions.
b. Data Quality: Maintaining high quality across all modalities to ensure effective training and reliable model performance.
c. Scalability: Handling large volumes of data from diverse sources while maintaining consistency and coherence.
d. Annotation Effort: The need for extensive and accurate annotations across multiple modalities, which can be resource-intensive.
Step-by-Step Implementation
Let’s walk through the process of implementing a multimodal learning model using Python and popular machine learning libraries like TensorFlow and PyTorch.
Step 1: Setting Up the Environment
First, ensure you have the necessary libraries installed. You can install them using pip:
pip install tensorflow keras transformers opencv-python
Step 2: Data Preparation
- Download COCO Dataset
Download the necessary COCO 2017 files (train images, val images, annotations) using this script:
import os, requests
from zipfile import ZipFile
urls = {
'train': 'http://images.cocodataset.org/zips/train2017.zip',
'val': 'http://images.cocodataset.org/zips/val2017.zip',
'annotations': 'http://images.cocodataset.org/annotations/annotations_trainval2017.zip'
}
def download_and_extract(url, path, extract_to):
if not os.path.exists(path):
response = requests.get(url)
with open(path, 'wb') as f:
f.write(response.content)
with ZipFile(path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
data_dir = 'coco_data'
os.makedirs(data_dir, exist_ok=True)
for url in urls.values():
download_and_extract(url, f'{data_dir}/{url.split("/")[-1]}', data_dir)
- Parse Annotations
Load and parse the COCO captions:
import json
from PIL import Image
with open(os.path.join(data_dir, 'annotations/captions_train2017.json'), 'r') as f:
annotations = json.load(f)
image_id_to_caption = {}
for ann in annotations['annotations']:
image_id_to_caption.setdefault(ann['image_id'], []).append(ann['caption'])
def load_image(image_id):
return Image.open(os.path.join(data_dir, 'train2017', f"{str(image_id).zfill(12)}.jpg"))
image = load_image(list(image_id_to_caption.keys())[0])
print(f"Captions: {image_id_to_caption[example_id]}")
image.show()
- Preprocess Data
Resize images and tokenize captions:
import numpy as np
from transformers import BertTokenizer
import cv2
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def preprocess(image_ids, image_folder, captions, tokenizer, max_len=128):
images, texts = [], []
for image_id in image_ids:
img = cv2.resize(cv2.imread(os.path.join(image_folder, f"{str(image_id).zfill(12)}.jpg")), (224, 224))
images.append(img)
tokenized = tokenizer(captions[image_id][0], return_tensors='tf', padding=True, truncation=True, max_length=max_len)
texts.append(tokenized['input_ids'])
return np.array(images), np.array(texts)
image_ids = list(image_id_to_caption.keys())[:100]
images, captions = preprocess(image_ids, os.path.join(data_dir, 'train2017'), image_id_to_caption, tokenizer)
- Prepare your text and image data.
For this example, we’ll use the COCO dataset, which contains images and corresponding captions.
import os
import cv2
import numpy as np
import pandas as pd
from transformers import BertTokenizer
# Load image data
image_folder = 'path/to/images'
images = []
for img_name in os.listdir(image_folder):
img_path = os.path.join(image_folder, img_name)
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
images.append(img)
images = np.array(images)
# Load text data
captions = pd.read_csv('path/to/captions.csv')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
texts = captions['caption'].tolist()
text_inputs = tokenizer(texts, return_tensors='tf', padding=True, truncation=True, max_length=128)
Step 3: Feature Extraction
Extract features from images using a pre-trained convolutional neural network (CNN) and from text using a pre-trained transformer model.
from tensorflow.keras.applications import ResNet50
from transformers import TFBertModel
# Load pre-trained models
image_model = ResNet50(weights='imagenet', include_top=False, pooling='avg')
text_model = TFBertModel.from_pretrained('bert-base-uncased')
# Extract image features
image_features = image_model.predict(images)
# Extract text features
text_features = text_model(text_inputs['input_ids'], attention_mask=text_inputs['attention_mask'])[0][:, 0, :]
Step 4: Modality Fusion
Combine the features from both modalities. There are various ways to fuse the features, such as concatenation, attention mechanisms, or more sophisticated approaches like bilinear pooling.
from tensorflow.keras.layers import Concatenate, Dense from tensorflow.keras.models import Model from tensorflow.keras import Input # Define input layers image_input = Input(shape=(2048,)) text_input = Input(shape=(768,)) # Concatenate features merged = Concatenate()([image_input, text_input]) # Add dense layers for prediction x = Dense(512, activation='relu')(merged) output = Dense(1, activation='sigmoid')(x) # Assuming a binary classification task # Create and compile the model model = Model(inputs=[image_input, text_input], outputs=output) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Step 5: Training the Model
Train the multimodal model on the combined data.
# Assuming you have labels for your data labels = captions['label'].values # Train the model model.fit([image_features, text_features], labels, epochs=10, batch_size=32, validation_split=0.2)
Step 6: Evaluation and Inference
Evaluate the model on a test set and perform inference.
# Load and prepare test data test_images = ... # Prepare test images as before test_texts = ... # Prepare test texts as before test_image_features = image_model.predict(test_images) test_text_inputs = tokenizer(test_texts, return_tensors='tf', padding=True, truncation=True, max_length=128) test_text_features = text_model(test_text_inputs['input_ids'], attention_mask=test_text_inputs['attention_mask'])[0][:, 0, :] # Evaluate the model test_labels = ... # Prepare test labels model.evaluate([test_image_features, test_text_features], test_labels) # Inference predictions = model.predict([test_image_features, test_text_features])
Advanced Techniques
Attention Mechanisms
Attention mechanisms can significantly enhance the performance of multimodal models by allowing the model to focus on relevant parts of the input data.
from tensorflow.keras.layers import Attention # Attention layer query = Dense(128)(text_input) key = Dense(128)(image_input) value = Dense(128)(image_input) attention_output = Attention()([query, key, value]) # Combine with other features merged = Concatenate()([attention_output, text_input]) x = Dense(512, activation='relu')(merged) output = Dense(1, activation='sigmoid')(x) # Create and compile the model model = Model(inputs=[image_input, text_input], outputs=output) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Transformer-Based Models
Using transformer-based models like CLIP (Contrastive Language-Image Pretraining) can provide powerful capabilities for multimodal learning.
from transformers import CLIPProcessor, CLIPModel
# Load CLIP model and processor
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Prepare data for CLIP
clip_inputs = clip_processor(text=texts, images=images, return_tensors="pt", padding=True)
# Extract features using CLIP
clip_outputs = clip_model(**clip_inputs)
text_features = clip_outputs.text_embeds
image_features = clip_outputs.image_embeds
# Combine and use in your model as before
Conclusion
Multimodal learning opens up new possibilities for creating more intelligent and capable AI systems. By effectively combining the strengths of different data modalities, we can achieve better performance on a wide range of tasks. The techniques and code examples provided in this article should serve as a solid foundation for exploring and implementing your own multimodal learning models.
