

Real-time stream processing has become a crucial aspect of managing live data streams and obtaining instant information. Kafka, a robust distributed streaming platform, when combined with Java forms a powerful duo for building scalable and efficient real-time stream processing applications.
In this article, we will look at the basics of building such an application, using Kafka and Java. We’ll see a clear structure, practical code examples, and an exploration of the intricacies involved.
Overview of Apache Kafka
Let’s look at the essence of real-time stream processing. Real-time stream processing relies on processing and analyzing data as it’s generated or ingested, facilitating immediate estimation and responses.
Apache Kafka, initially developed by LinkedIn and later open-sourced as an Apache Software Foundation project, serves as a distributed event streaming platform. Unlike traditional messaging systems, Kafka excels in handling streams of records in a fault-tolerant and scalable manner. It is particularly designed for scenarios where data needs to be processed in real-time, making it a crucial technology for modern data-driven applications, especially when paired with Java development services to build robust and efficient solutions.
Kafka, an open-source distributed data store, stands out as an event streaming platform, making it an ideal choice for developing real-time applications.
So, the most likely question is: why Kafka? Kafka’s architecture, based on distributed commit logs, guarantees fault tolerance, scalability, and reliability. Its ability to manage large-scale data streams with low-latency processing makes it the tool of choice in various industries, from finance to e-commerce.
Use Cases of Apache Kafka
Log Aggregation: Kafka is widely used to aggregate log data from various applications and systems, providing a centralized platform for monitoring and analysis.
Event Sourcing: In event-driven architectures, Kafka serves as a reliable event store, allowing applications to maintain a complete record of events for auditing and analysis.
Microservices Communication: Kafka acts as a communication backbone for microservices, facilitating the exchange of messages between different services in a scalable and fault-tolerant manner.
Data Integration: Kafka simplifies the integration of disparate data sources, allowing real-time data flow between applications and systems.
Key Components of Apache Kafka
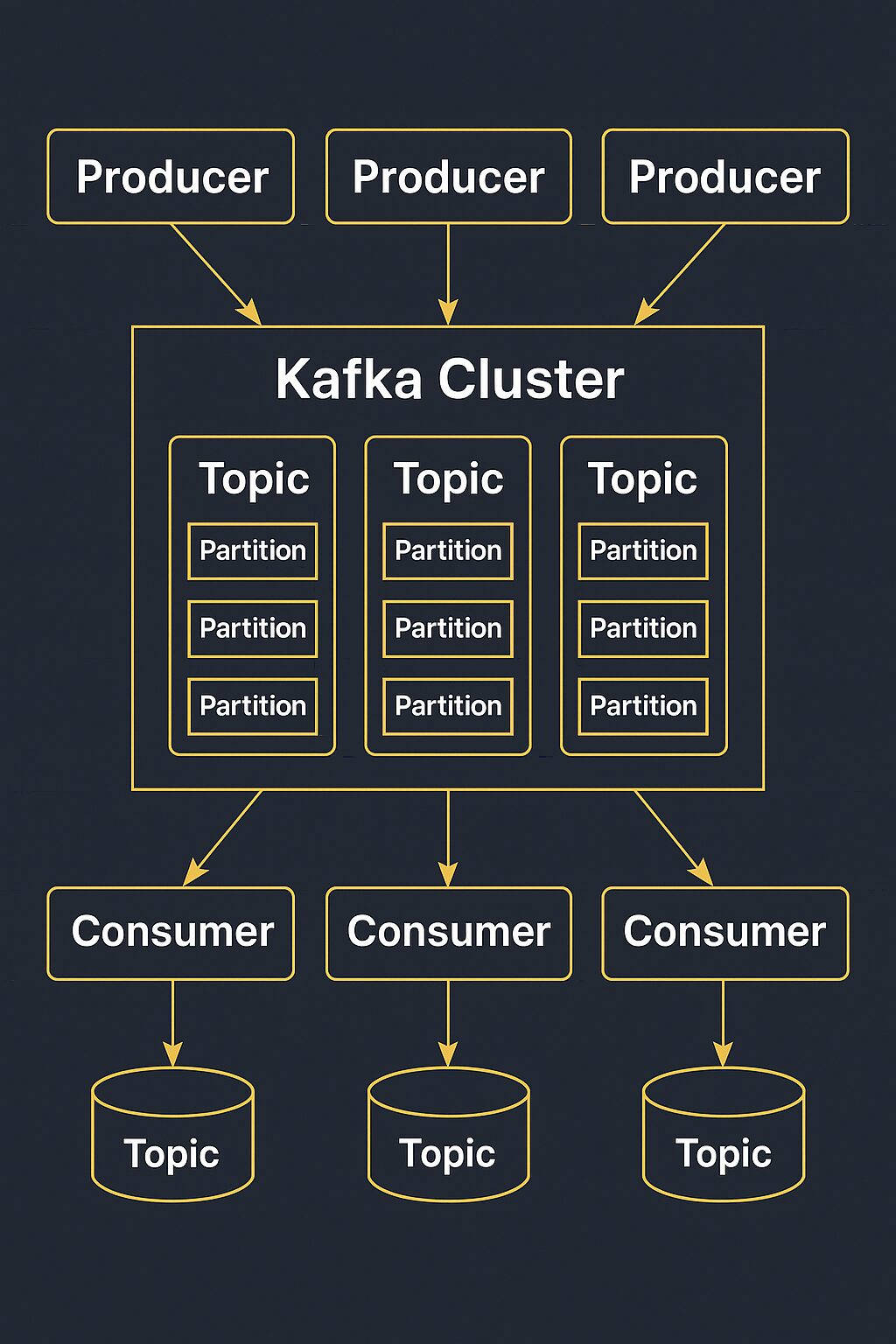
- Producer: In the Kafka ecosystem, a producer is responsible for publishing records to one or more Kafka topics. The topic is the most important abstraction provided by Kafka: it is a category or feed name to which data is published by producers.
- Broker: Kafka runs in a distributed environment with a cluster of brokers. Each broker stores the data and serves clients. The distributed nature of brokers provides fault tolerance and scalability.
- Consumer: Consumers subscribe to one or more topics and process the stream of records produced to those topics. Kafka consumers can be part of a consumer group, which enables parallel processing of data for improved performance.
- Topic: A topic is a category or name of the channel in which records are published. Topics allow you to organize and segment data streams.
- Zookeeper: While Kafka is known for its distributed architecture, it relies on Apache ZooKeeper to manage and coordinate the Kafka brokers in the cluster.
Before diving into application development, it’s essential to set up Apache Kafka. Below is a step-by-step guide to get you started:
A. Kafka Installation
- Download Kafka: Visit the official website Apache Kafka Downloads and download the Kafka distribution package.
- Extract Kafka: Once the download is complete, extract the downloaded archive
B. Initiate Zookeeper

C. Start Kafka Server

Now let’s kick off the construction of our real-time stream processing application with a Kafka producer in Java.
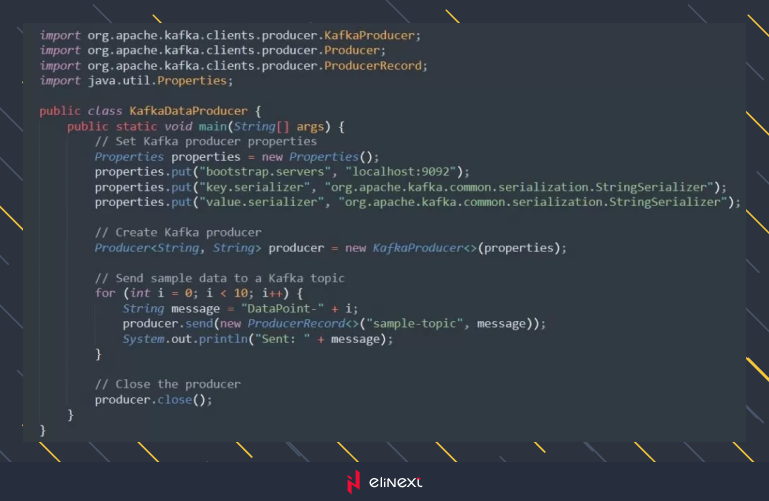
This Java program establishes a Kafka producer, configures connection properties, and dispatches sample data to a Kafka topic.
Kafka in Action: An Example of Real-Time Streaming
To illustrate the capabilities of Apache Kafka, let’s look at a real-time streaming example showing how Kafka can be use
d to create a real-time streaming application for monitoring and analyzing Twitter feeds.
Step 1: Get Twitter Data
The process begins with the Twitter API acting as the producer, streaming live tweets to a Kafka topic. This demonstrates the flexibility of Kafka to seamlessly integrate with various data sources.
Step 2: Kafka Topic and Brokers
The tweets are then published to a Kafka topic, acting as a centralized channel for storing and organizing data in real-time. Kafka brokers, distributed across a cluster, ensure resiliency and scalability by efficiently processing incoming traffic.
Step 3: Real Time Data Processing
Multiple consumers subscribe to the Kafka topic and process the incoming tweets in real-time. This step demonstrates Kafka’s ability to facilitate parallel processing across groups of consumers, enabling the system to handle high-throughput scenarios.
Step 4: Data Analytics and Visualization
The processed data is then sent to analytics tools for further data analysis and visualization. This final step highlights the versatility of Kafka in integrating seamlessly with downstream applications, making it a crucial component in end-to-end data processing pipelines.
Now, let’s see how to build a Kafka consumer to process the real-time data.
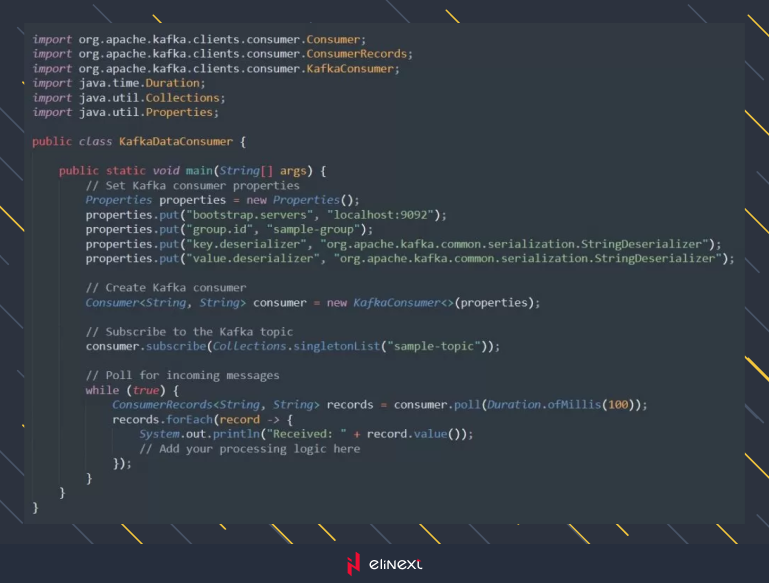
This consumer subscribes to the “sample-topic” and continually polls for incoming messages, displaying them on the console.
Let’s enhance our consumer by incorporating a simple real-time processing logic using Java Streams.
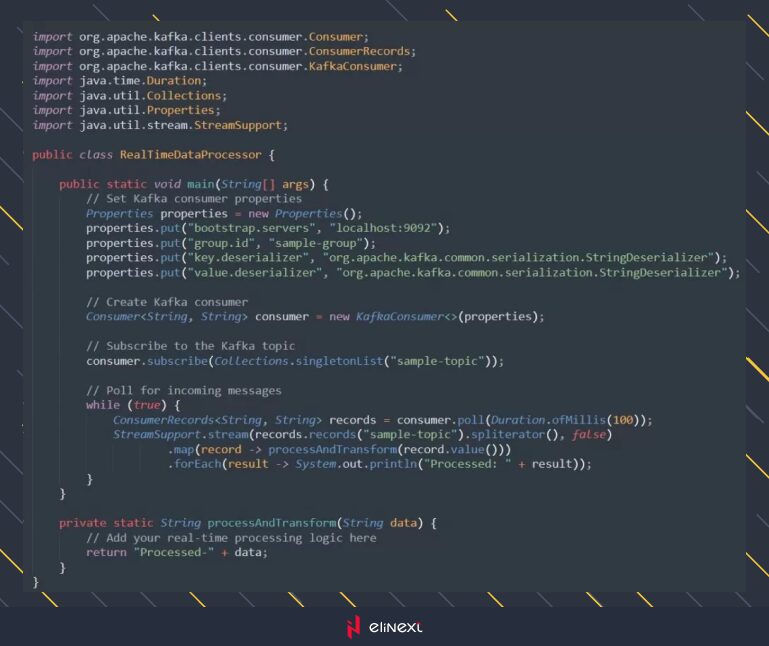
This example includes the `processAndTransform` method, representing custom real-time processing logic. We can adapt it based on your application’s requirements.
Advanced Kafka Concepts
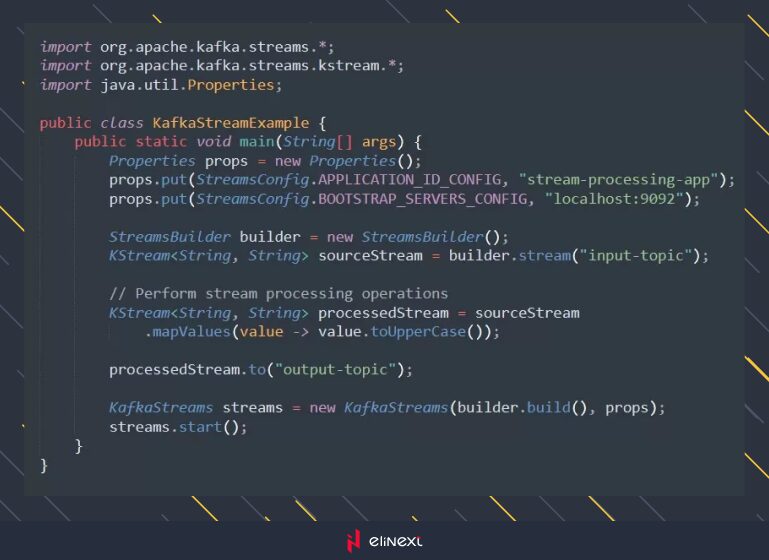
- Kafka streams
Kafka Streams is a client library for building real-time streaming applications on top of Kafka. It allows developers to process and analyze data streams using the scalability and fault tolerance of Kafka. Here’s a Java example illustrating the use of Kafka Streams for real-time data processing:
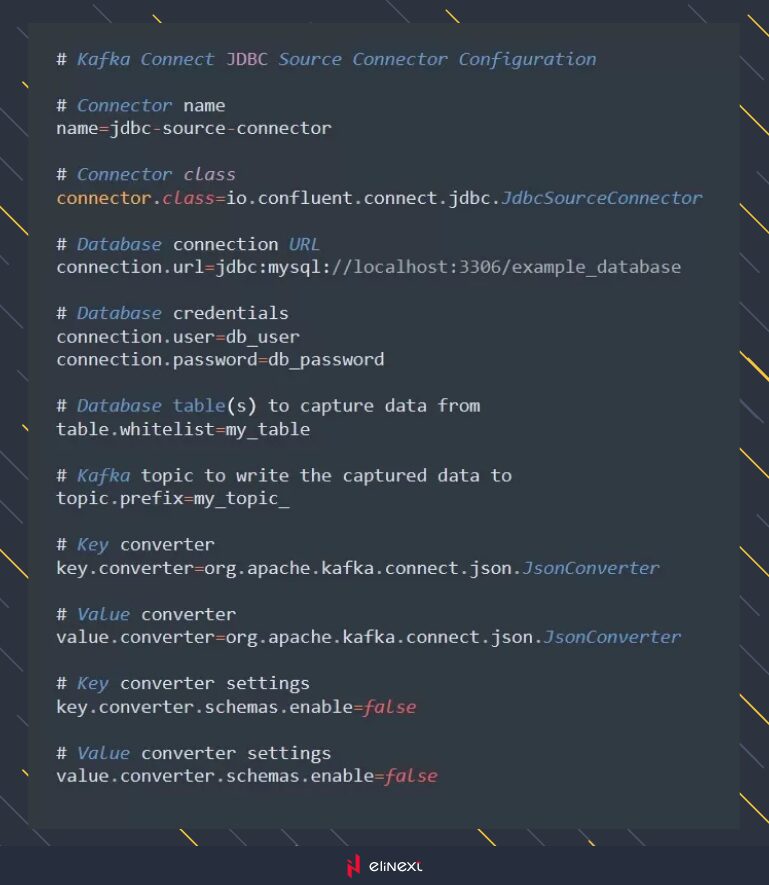
Kafka Connect
Kafka Connect is a framework for building and running reusable data import/export connectors to Kafka. It simplifies the integration of Kafka with external systems, enabling seamless data movement. Let’s consider an example of using Kafka Connect with JDBC source connector to capture data changes from a relational database:
Real-World Use Cases
- Real-Time Analytics
Kafka’s ability to process and analyze data streams in real-time makes it ideal for real-time analytics use cases. Organizations can ingest data from various sources, perform analytics on-the-fly, and derive valuable insights. For instance, a retail company can analyze customer transactions in real-time to personalize offers and promotions.
- Log Aggregation
Kafka is widely used for log aggregation, collecting logs from multiple sources and centralizing them for monitoring and analysis. By leveraging Kafka’s distributed architecture, organizations can handle large volumes of log data efficiently. This is particularly beneficial for troubleshooting and debugging in complex systems.
- Microservices Communication
In a microservices architecture, Kafka serves as a reliable communication channel between microservices. It enables asynchronous communication, decoupling services and improving scalability and fault tolerance. Microservices can publish events to Kafka topics, allowing other services to consume them as needed.
As we can conclude from the information above, constructing a real-time stream processing application with Kafka and Java involves Kafka setup, producer and consumer creation, and the incorporation of real-time processing logic. The provided examples lay the foundation for our exploration into the dynamic realm of real-time data handling.
Apache Kafka, with its advanced features and ecosystem, has revolutionized real-time data streaming and processing. By mastering advanced Kafka concepts and utilizing Java for implementation, developers can build scalable, fault-tolerant, and real-time streaming applications. From stream processing with Kafka Streams to data integration with Kafka Connect, the possibilities are endless. Embracing Kafka’s capabilities empowers organizations to unlock the full potential of their real-time data.
